If you’ve successfully stripped down a Raspberry Pi 4B to run a sub-1B parameter model at blazing speeds, you’ve won the hardware battle. You have a local, lightning-fast logic router. But speed without accuracy is just generating garbage at 100km/h.
When building autonomous systems—like the kheAI Agentic Capybara—the goal is Mind Sovereignty. We want agents that can evaluate data, sign JSON objects, and execute local commands without “phoning home” to a Big Tech cloud provider and paying an intelligence tax.
The problem? A 0.8B model (like Qwen) is too small to memorize the world, and it is too “creative” to consistently output machine-readable code. To fix this, we don’t need a bigger model; we need to upgrade the model’s environment. We must stop treating AI as a chatbot and start treating it as a Deterministic Software Component.
Here is how I build a better cage for the brain we have, transforming a simple Raspberry Pi 4B into a Sovereign Edge Agent.
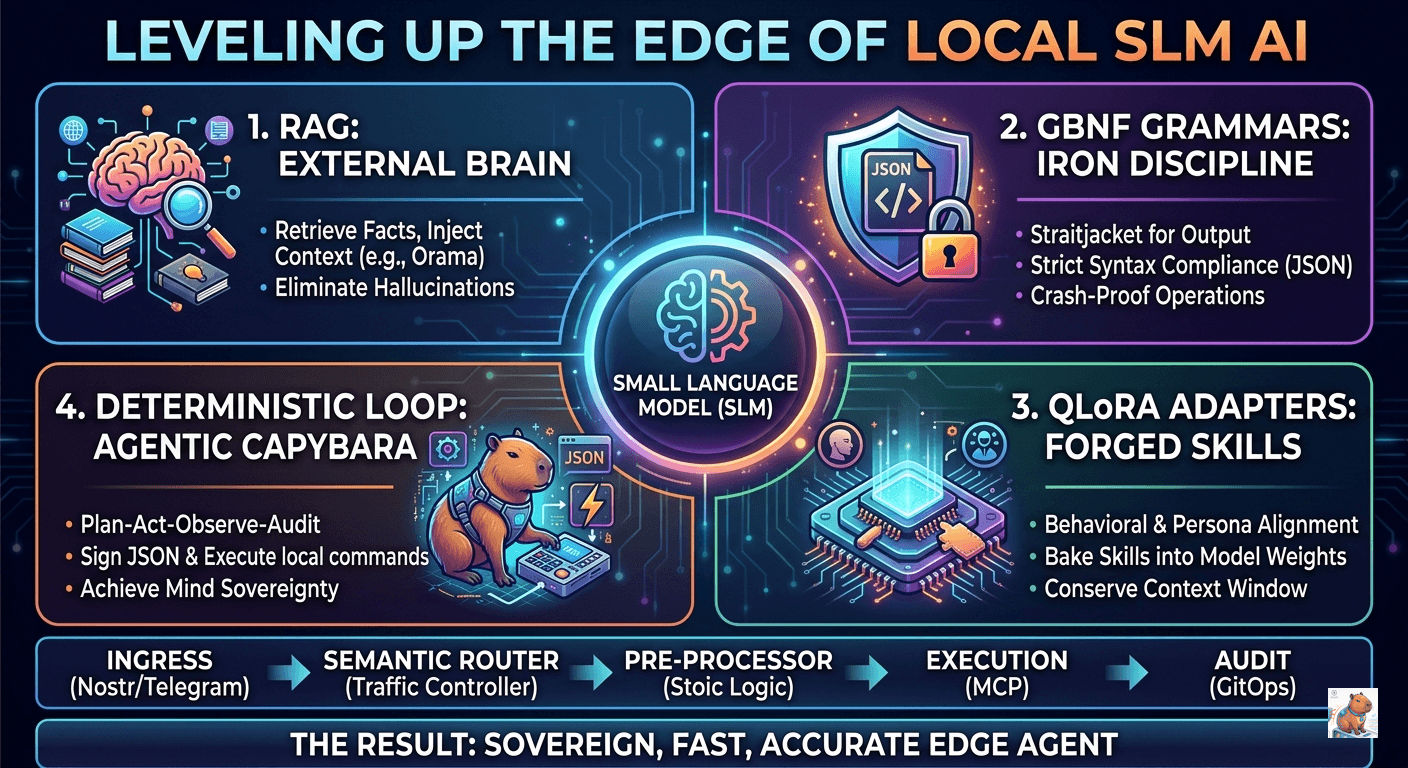
Phase 1: The Core Triumvirate
To get a 0.8B model to act as a reliable agent, you must solve three problems: Factual recall, syntax integrity, and behavioral alignment.
1. RAG: The External Brain
There is a persistent myth in the AI community: If you want a model to learn new facts, fine-tune it. For an SLM (Small Language Model), this is a trap. Attempting to carve an encyclopedia into a 0.8B grain of rice results in “Catastrophic Forgetting”—the model overwrites its existing logic to make room for names and dates, eventually becoming a hallucinating mess.
Retrieval-Augmented Generation (RAG) is the local solution. Think of the 0.8B model as a fast reader with amnesia. It doesn’t know anything, but if you hand it a page of text, it can summarize it perfectly.
The Local RAG Engineering Loop:
- The Interception: A Node.js backend intercepts the user query.
- The Retrieval: It searches a local Orama or SQLite database for relevant snippets.
- The Context Injection: It wraps the retrieved facts in a hidden system prompt.
Instead of the model guessing the status of the Puchong node, the RAG system intercepts and injects: “Context: Puchong Node was last seen 4 mins ago. Answer only using context.” By doing this, you preserve 100% of the model’s reasoning power for processing information rather than recalling it.
2. GBNF Grammars: The Syntax Straitjacket
If your AI is meant to be an autonomous agent—signing JSON objects or triggering hardware—it cannot afford to be conversational. If a 0.8B model adds a single “Here is your JSON:” or a stray comma, your Node.js parser will crash.
You cannot prompt-engineer your way out of this on an SLM. You have to physically restrict the model’s ability to choose tokens using GBNF (GGML BNF) grammars.
GBNF acts like a RegEx for inference. Instead of letting the model predict any word in the dictionary, the grammar forces the model to only select tokens that fit a specific mathematical schema.
| Feature | Without GBNF | With GBNF |
|---|---|---|
| Consistency | High risk of “yapping” | 100% Schema compliance |
| Logic | May fail to close brackets | Mathematically forced closure |
| Reliability | Requires complex error handling | Predictable, machine-readable output |
When the agent needs to decide whether to zap a Lightning invoice or ignore a Nostr post, a GBNF grammar ensures the output is strictly {"action": "zap", "amount": 21} and never {"action": "zap!"}.
3. QLoRA Adapters: The Behavioral Patch
RAG solves what the model knows. GBNF solves how it formats. QLoRA (Quantized Low-Rank Adaptation) solves how the model behaves.
System prompts eat up your precious Context Window and weaken a small model’s focus. QLoRA allows you to bake a specific skill—like “Nostr Protocol Signing” or a Stoic minimalist persona—directly into the model’s weights as a tiny 50MB patch file.
You train the LoRA offline on a GPU with 1,000 examples of your desired behavior, then load it alongside your base model on the Pi using llama.cpp. The model “wakes up” with the persona already active.
Phase 2: Architectural Efficiency
Once the core is stable, we move away from brute-force inference. To make the RPi 4B truly viable, we stack these efficiency layers on top:
Semantic Routing (The Traffic Controller)
Instead of forcing every input through an expensive LLM cycle, use a Semantic Router. When an input comes in, the router classifies it (e.g., [HARDWARE_CONTROL], [GENERAL_QUERY], [STOIC_ADVICE]). Only complex queries hit the inference engine. Everything else triggers a deterministic, lightweight script.
Semantic Caching (In-Process Habit Memory)
Traditional RAG re-calculates embeddings every time. Semantic Caching (using lightweight WASM libraries) stores previous intents and their results. If a user asks a similar question tomorrow, the Pi returns the cached result instantly without ever waking up the LLM.
Speculative Decoding (The Draft & Verify Loop)
Use a tiny “Draft” model to rapidly guess the next few tokens, and a slightly larger “Target” model to verify them in a single pass. If the draft model is right 70% of the time, the Pi only spends heavy compute on the 30% it gets wrong, drastically reducing latency.
GraphRAG & LightKGG (Relational Reasoning)
Standard RAG treats data as flat text. Agents need to understand relationships. Frameworks like LightKGG allow SLMs to extract Knowledge Graphs, letting your agent navigate a “Map” of your business logic (e.g., “If the Bitcoin Lightning node is down, the ‘Zap’ tool will fail”).
Model Context Protocol (MCP) & Agent-to-Agent (A2A)
To function as an “Entity as a Service,” the agent needs standardization. MCP standardizes how the agent connects to local files, GitOps repos, and hardware sensors. For A2A, we use the Nostr network as the coordination layer. The Pi acts as a Sovereign Gateway, delegating sub-tasks to other local devices via encrypted Nostr events.
The Unified Sovereign Stack
Bringing it all together, here is the flow for a resilient, autonomous edge device:
| Layer | Technology | Functional Role |
|---|---|---|
| Ingress | Nostr / Telegram | Secure, decentralized entry point for commands. |
| Logic Router | Semantic Router + Qwen 0.8B | Determines if the task needs “Brain” or deterministic “Code.” |
| Pre-Processor | Stoic Logic Core | Filters out noise or emotional prompts using Enchiridion-based grounding. |
| Memory & Skill | Orama (RAG) + QLoRA | Injects dynamic facts and permanent behavioral alignment. |
| Action | MCP + GBNF | Ensures the hardware command is perfectly formatted JSON. |
| Audit | GitOps | Every successful action is committed to a local Git log for perfect auditability. |
(Pro-Tip: If you ever feel the Pi 4B is truly red-lining, look into Collaborative Inference. You can split the layers of a model across two RPis on the same local network, effectively doubling your VRAM without leaving your digital sovereign perimeter).
By building a better environment around a small model, you can absolutely achieve Mind Sovereignty on the edge.